- What is vocoder in speech synthesis?
- What is Vocoding used for?
- What is vocoder in deep learning?
- What is a vocoder model?
What is vocoder in speech synthesis?
A vocoder (/ˈvoʊkoʊdər/, a portmanteau of voice and encoder) is a category of speech coding that analyzes and synthesizes the human voice signal for audio data compression, multiplexing, voice encryption or voice transformation.
What is Vocoding used for?
The vocoder was developed in 1928 by Bell Labs, and first demonstrated in 1939 at the New York World's Fair. Its intended use was to reduce the bandwidth of voice information, allowing it to be transferred across further distances.
What is vocoder in deep learning?
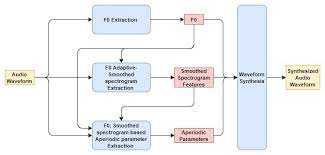
Deep learning speech synthesis uses Deep Neural Networks (DNN) to produce artificial speech from text (text-to-speech) or spectrum (vocoder). The deep neural networks are trained using a large amount of recorded speech and, in the case of a text-to-speech system, the associated labels and/or input text.
What is a vocoder model?
The word vocoder is an abbreviation for voice encoder. A vocoder analyzes and transfers the sonic character of the audio signal arriving at its analysis input to synthesizer sound generators. The result of this process is heard at the output of the vocoder.


